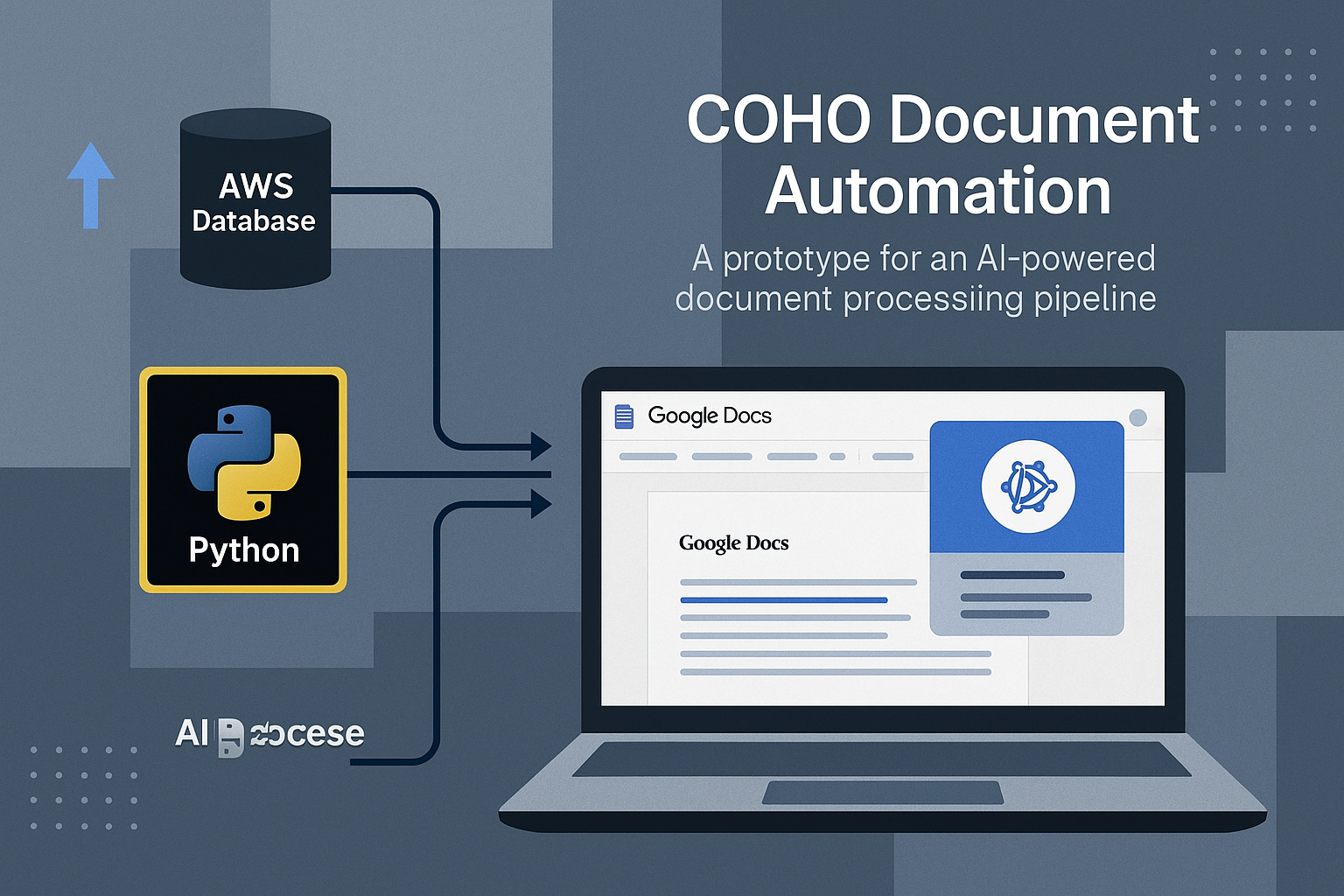
The Challenge
To create a scalable backend pipeline that could ingest, process, and extract structured data from unstructured document sources efficiently.
The Solution
Built a pipeline integrating FastAPI endpoints with Supabase Storage and the OpenAI API. Uploaded documents were parsed, processed, and summarized into structured JSON for analytics or further processing.
Key Features
- Document upload and storage via Supabase
- FastAPI endpoints for asynchronous processing
- OpenAI text extraction and summarization
- JSON schema mapping for downstream apps
- Early-stage Angular interface for monitoring tasks
Technical Approach
- Backend: FastAPI async routes and task queue system
- AI Integration: GPT-4 model for entity extraction
- Data Storage: Supabase tables for job states and results
- Security: JWT-protected endpoints with CORS configuration
Code Highlights
# main.py
@app.post("/process-document/")
async def process_document(file: UploadFile):
text = extract_text(await file.read())
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": f"Summarize this:\n{text}"}]
)
return {"summary": response.choices[0].message.content}
Processes uploaded documents and summarizes them using GPT-4.
Results & Impact
- ⚙️ Reduced manual processing time significantly
- 📄 Reliable schema generation for document metadata
- 🚀 Prototype used as base for future enterprise deployment
Lessons Learned
Combining AI with strict backend architecture taught valuable lessons about prompt stability and rate limits.